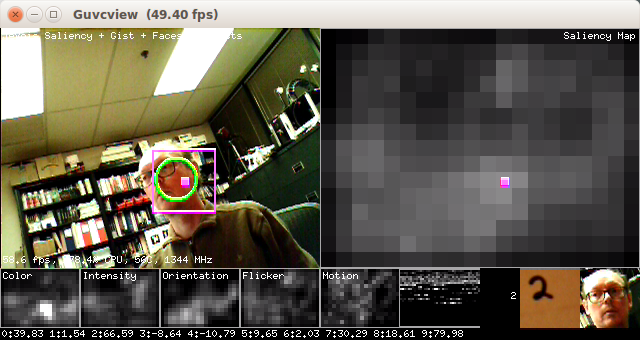
Run the visual saliency algorithm to find the most interesting location in the field of view. Then extract a square image region around that point. On alternating frames, either
- attempt to detect a face in the attended region, and, if positively detected, show the face in the bottom-right corner of the display. The last detected face will remain shown in the bottom-right corner of the display until a new face is detected.
- or attempt to recognize an object in the attended region, using a deep neural network. The default network is a handwritten digot recognition network that replicated the original LeNet by Yann LeCun and is one of the very first convolutional neural networks. The network has been trained on the standard MNIST database of handwritten digits, and achives over 99% correct recognition on the MNIST test dataset. When a digit is positively identified, a picture of it appears near the last detected face towards the bottom-right corner of the display, and a text string with the digit that has been identified appears to the left of the picture of the digit.
Serial Messages
This module can send standardized serial messages as described in Standardized serial messages formatting, where all coordinates and sizes are standardized using Helper functions to convert coordinates from camera resolution to standardized. One message is issued on every video frame at the temporally filtered attended (most salient) location (green circle in the video display):
- Serial message type: 2D
id: always sm (shorthand for saliency map)x, y: standardized 2D coordinates of temporally-filtered most salient pointw, h: standardized size of the pink square box around each attended pointextra: none (empty string)
See Standardized serial messages formatting for more on standardized serial messages, and Helper functions to convert coordinates from camera resolution to standardized for more info on standardized coordinates.