|
| By Laurent Itti | itti@usc.edu | http://jevois.org | GPL v3 |
| |||
| Video Mapping: NONE 0 0 0.0 YUYV 640 480 15.0 JeVois DetectionDNN | |||
| Video Mapping: YUYV 640 498 15.0 YUYV 640 480 15.0 JeVois DetectionDNN |
Module Documentation
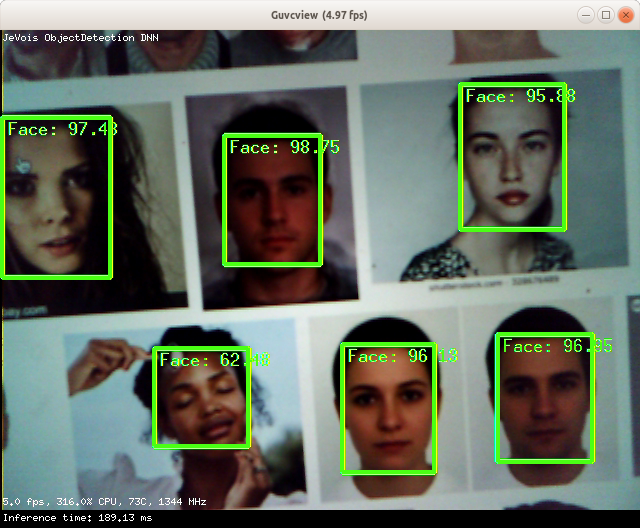
This module runs an object detection deep neural network using the OpenCV DNN library. Detection networks analyze a whole scene and produce a number of bounding boxes around detected objects, together with identity labels and confidence scores for each detected box.
This module runs the selected deep neural network and shows all detections obtained.
Note that by default this module runs the OpenCV Face Detector DNN which can detect human faces.
Included with the standard JeVois distribution are the following networks:
- OpenCV Face Detector, Caffe model
- MobileNet + SSD trained on Pascal VOC (20 object classes), Caffe model
- MobileNet + SSD trained on Coco (80 object classes), TensorFlow model
- MobileNet v2 + SSD trained on Coco (80 object classes), TensorFlow model
- Darknet Tiny YOLO v3 trained on Coco (80 object classes), Darknet model
- Darknet Tiny YOLO v2 trained on Pascal VOC (20 object classes), Darknet model
See the module's params.cfg file to switch network. Object categories are as follows:
- The 80 COCO object categories are: person, bicycle, car, motorbike, aeroplane, bus, train, truck, boat, traffic, fire, stop, parking, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports, kite, baseball, baseball, skateboard, surfboard, tennis, bottle, wine, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot, pizza, donut, cake, chair, sofa, pottedplant, bed, diningtable, toilet, tvmonitor, laptop, mouse, remote, keyboard, cell, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy, hair, toothbrush.
- The 20 Pascal-VOC object categories are: aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tvmonitor.
Sometimes it will make mistakes! The performance of yolov3-tiny is about 33.1% correct (mean average precision) on the COCO test set. The OpenCV Face Detector is quite fast and robust!
Speed and network size
The parameter netin allows you to rescale the neural network to the specified size. Beware that this will only work if the network used is fully convolutional (as is the case with the default networks listed above). This not only allows you to adjust processing speed (and, conversely, accuracy), but also to better match the network to the input images (e.g., the default size for tiny-yolo is 416x416, and, thus, passing it a input image of size 640x480 will result in first scaling that input to 416x312, then letterboxing it by adding gray borders on top and bottom so that the final input to the network is 416x416). This letterboxing can be completely avoided by just resizing the network to 320x240.
Here are expected processing speeds for the OpenCV Face Detector:
- when netin = [320 240], processes 320x240 inputs, about 650ms/image (1.5 frames/s)
- when netin = [160 120], processes 160x120 inputs, about 190ms/image (5.0 frames/s)
Serial messages
When detections are found which are above threshold, one message will be sent for each detected object (i.e., for each box that gets drawn when USB outputs are used), using a standardized 2D message:
- Serial message type: 2D
id: the category of the recognized object, followed by ':' and the confidence score in percentx,y, or vertices: standardized 2D coordinates of object center or cornersw,h: standardized object sizeextra: any number of additional category:score pairs which had an above-threshold score for that box
See Standardized serial messages formatting for more on standardized serial messages, and Helper functions to convert coordinates from camera resolution to standardized for more info on standardized coordinates.
This code is heavily inspired from: https://github.com/opencv/opencv/blob/master/samples/dnn/object_detection.cpp
| Parameter | Type | Description | Default | Valid Values |
|---|---|---|---|---|
| (DetectionDNN) model | Model | Shortcut parameter to load a model. This sets parameters classnames, configname, modelname, etc for the selected network. When the selected model is Custom, those other parameters will be set instead from the module's params.cfg config file. | Model::Custom | Model_Values |
| (DetectionDNN) classnames | std::string | Path to a text file with names of classes to label detected objects | JEVOIS_SHARE_PATH /opencv-dnn/detection/opencv_face_detector.classes | - |
| (DetectionDNN) configname | std::string | Path to a text file that contains network configuration. Can have extension .prototxt (Caffe), .pbtxt (TensorFlow), or .cfg (Darknet). | JEVOIS_SHARE_PATH /opencv-dnn/detection/opencv_face_detector.prototxt | - |
| (DetectionDNN) modelname | std::string | Path to a binary file of model contains trained weights. Can have extension .caffemodel (Caffe), .pb (TensorFlow), .t7 or .net (Torch), or .weights (Darknet). | JEVOIS_SHARE_PATH /opencv-dnn/detection/opencv_face_detector.caffemodel | - |
| (DetectionDNN) netin | cv::Size | Width and height (in pixels) of the neural network input layer, or [0 0] to make it match camera frame size. NOTE: for YOLO v3 sizes must be multiples of 32. | cv::Size(160, 120) | - |
| (DetectionDNN) thresh | float | Detection threshold in percent confidence | 50.0F | jevois::Range<float>(0.0F, 100.0F) |
| (DetectionDNN) nms | float | Non-maximum suppression intersection-over-union threshold in percent | 45.0F | jevois::Range<float>(0.0F, 100.0F) |
| (DetectionDNN) rgb | bool | When true, model works with RGB input images instead BGR ones | true | - |
| (DetectionDNN) scale | float | Value scaling factor applied to input pixels | 2.0F / 255.0F | - |
| (DetectionDNN) mean | cv::Scalar | Mean BGR value subtracted from input image | cv::Scalar(127.5F, 127.5F, 127.5F) | - |
params.cfg file# Parameter file for DetectionDNN. You can select a neural network to run here:
# You can either just set parameter 'model' to any of:
# Custom, Face, MobileNetSSDvoc, MobileNetSSDcoco, MobileNet2SSDcoco, TinyYOLOv3, TinyYOLOv2
model = MobileNetSSDvoc
# Or, set Model to Custom and then set the individual model parameters one by one (useful for custom models beyond the
# sample models provided here):
# OpenCV Face Detector, Caffe model
#classnames = /jevois/share/opencv-dnn/detection/opencv_face_detector.classes
#modelname = /jevois/share/opencv-dnn/detection/opencv_face_detector.caffemodel
#configname = /jevois/share/opencv-dnn/detection/opencv_face_detector.prototxt
#scale = 1.0
#mean = 104.0 177.0 123.0
#rgb = false
# MobileNet v2 + SSD trained on Coco (90 object classes), TensorFlow model
#classnames = /jevois/share/opencv-dnn/detection/coco_tf.names
#modelname = /jevois/share/opencv-dnn/detection/ssd_mobilenet_v2_coco_2018_03_29.pb
#configname = /jevois/share/opencv-dnn/detection/ssd_mobilenet_v2_coco_2018_03_29.pbtxt
# MobileNet + SSD trained on Pascal VOC (20 object classes), Caffe model
#classnames = /jevois/share/darknet/yolo/data/voc.names
#modelname = /jevois/share/opencv-dnn/detection/MobileNetSSD_deploy.caffemodel
#configname = /jevois/share/opencv-dnn/detection/MobileNetSSD_deploy.prototxt
#rgb = false
# MobileNet + SSD trained on Coco (90 object classes), TensorFlow model
#classnames = /jevois/share/opencv-dnn/detection/coco_tf.names
#modelname = /jevois/share/opencv-dnn/detection/ssd_mobilenet_v1_coco_2017_11_17.pb
#configname = /jevois/share/opencv-dnn/detection/ssd_mobilenet_v1_coco_2017_11_17.pbtxt
#rgb = false
#nms = 10.0
# Darknet Tiny YOLO v3 trained on Coco (80 object classes), Darknet model
#classnames = /jevois/share/darknet/yolo/data/coco.names
#modelname = /jevois/share/darknet/yolo/weights/yolov3-tiny.weights
#configname = /jevois/share/darknet/yolo/cfg/yolov3-tiny.cfg
# Darknet Tiny YOLO v2 trained on Pascal VOC (20 object classes), Darknet model
#classnames = /jevois/share/darknet/yolo/data/voc.names
#modelname = /jevois/share/darknet/yolo/weights/yolov2-tiny-voc.weights
#configname = /jevois/share/darknet/yolo/cfg/yolov2-tiny-voc.cfg
#netin = 320 240
|
| Detailed docs: | DetectionDNN |
|---|---|
| Copyright: | Copyright (C) 2018 by Laurent Itti, iLab and the University of Southern California |
| License: | GPL v3 |
| Distribution: | Unrestricted |
| Restrictions: | None |
| Support URL: | http://jevois.org/doc |
| Other URL: | http://iLab.usc.edu |
| Address: | University of Southern California, HNB-07A, 3641 Watt Way, Los Angeles, CA 90089-2520, USA |