|
| By Laurent Itti | itti@usc.edu | http://jevois.org | GPL v3 |
| |||
| Video Mapping: JVUI 0 0 30.0 YUYV 1920 1080 30.0 JeVois PyLLM |
Module Documentation
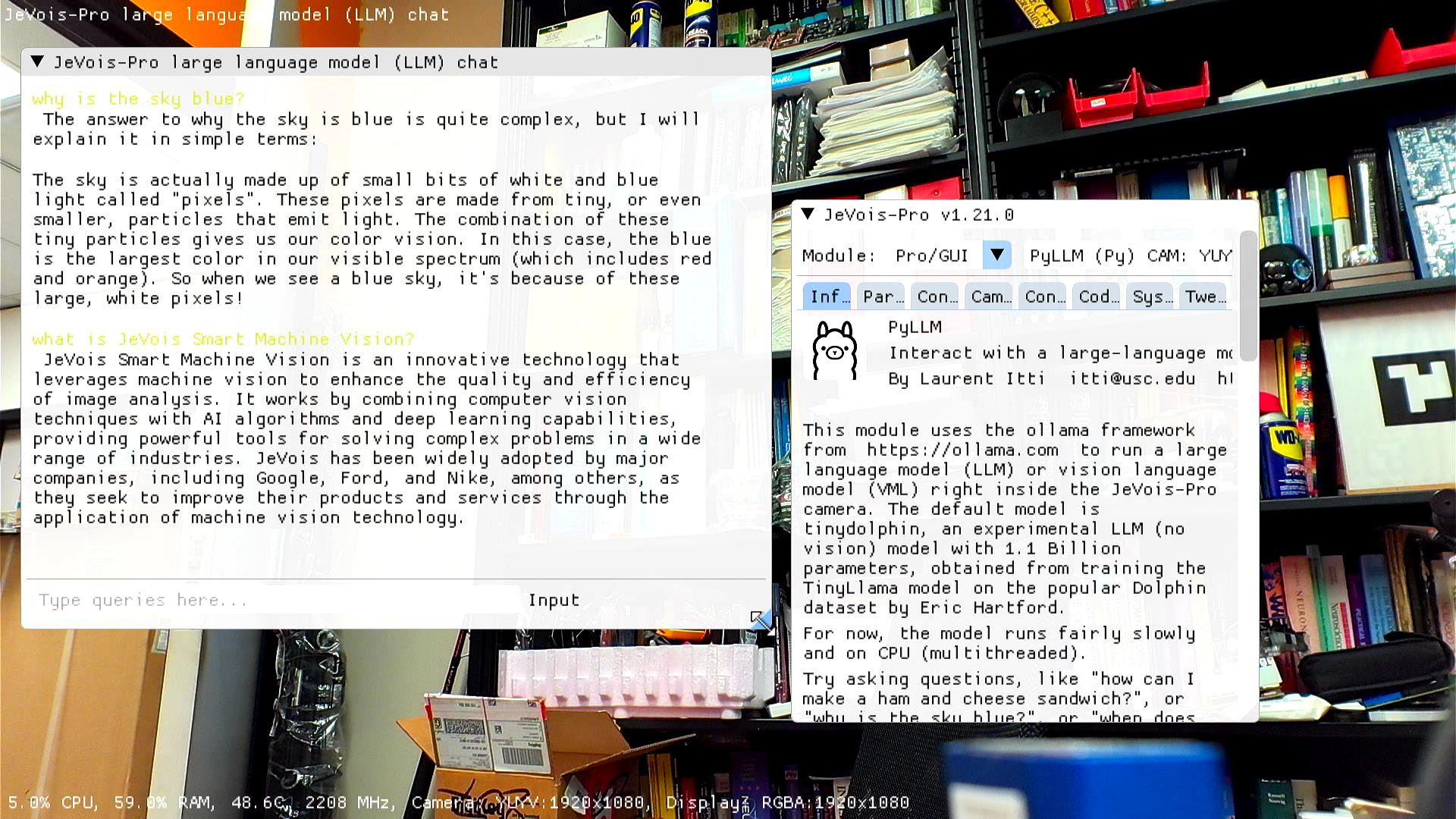
This module uses the ollama framework from https://ollama.com to run a large language model (LLM) or vision language model (VLM) right inside the JeVois-Pro camera. The default model is tinydolphin, an experimental LLM (no vision) model with 1.1 Billion parameters, obtained from training the TinyLlama model on the popular Dolphin dataset by Eric Hartford.
For now, the model runs fairly slowly and on CPU (multithreaded).
Try asking questions, like "how can I make a ham and cheese sandwich?", or "why is the sky blue?", or "when does summer start?", or "how does asyncio work in Python?"
Also pre-loaded on microSD is moondream2 with 1.7 Billion parameters, a VLM that can both answer text queries, and also describe images captured by JeVois-Pro, and answer queries about them. However, this model is very slow as just sending one image to it as an input is like sending it 729 tokens... So, consider it an experimental feature for now. Hopefully smaller models will be available soon.
With moondream, you can use the special keyword /videoframe/ to pass the current frame from the live video to the model. You can also add more text to the query, for example:
user: /videoframe/ how many people? moondream: there are five people in the image.
If you only input /videoframe/ then the following query text is automatically added: "Describe this image:"
This module uses the ollama python library from https://github.com/ollama/ollama-python
More models
Other models can run as well. The main question is how slowly, and will we run out or RAM or out of space on our microSD card? Have a look at https://ollama.com for supported models. You need a working internet connection to be able to download and install new models. Installing new models may involve lengthy downloads and possible issues with the microSD getting full. Hence, we recommend that you restart JeVois-Pro to ubuntu command-line mode (see under System tab of the GUI), then login as root/jevois, then:
df -h / # check available disk space ollama list # shows instaled models ollama rm somemodel # delete some installed model if running low on disk space ollama run newmodel # download and run a new model, e.g., tinyllama (<2B parameters recommended); if you like it, exit ollama (CTRL-D), and run jevoispro.sh to try it out in the JeVois-Pro GUI.
Disclaimer
LLM research is still in early stages, despite the recent hype. Remember that these models may return statements that may be inaccurate, biased, possibly offensive, factually wrong, or complete garbage. At then end of the day, always remember that: it's just next-token prediction. You are not interacting with a sentient, intelligent being.
| Parameter | Type | Description | Default | Valid Values |
|---|---|---|---|---|
| This module exposes no parameter | ||||
| Detailed docs: | PyLLM |
|---|---|
| Copyright: | Copyright (C) 2024 by Laurent Itti, iLab and the University of Southern California |
| License: | GPL v3 |
| Distribution: | Unrestricted |
| Restrictions: | None |
| Support URL: | http://jevois.org/doc |
| Other URL: | http://iLab.usc.edu |
| Address: | University of Southern California, HNB-07A, 3641 Watt Way, Los Angeles, CA 90089-2520, USA |