|
| By Laurent Itti | itti@usc.edu | http://jevois.org | GPL v3 |
| |||
| Video Mapping: NONE 0 0 0.0 YUYV 320 240 30.0 JeVois TensorFlowSingle | |||
| Video Mapping: YUYV 560 240 15.0 YUYV 320 240 15.0 JeVois TensorFlowSingle | |||
| Video Mapping: YUYV 464 240 15.0 YUYV 320 240 15.0 JeVois TensorFlowSingle | |||
| Video Mapping: YUYV 880 480 15.0 YUYV 640 480 15.0 JeVois TensorFlowSingle |
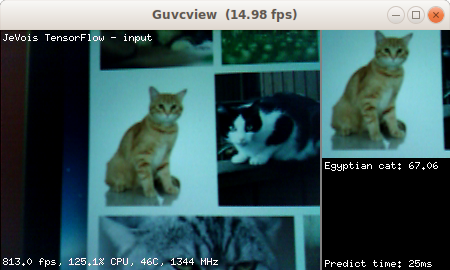

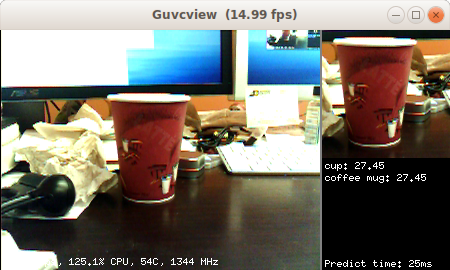
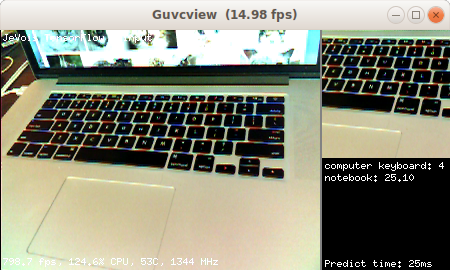


Module Documentation
TensorFlow is a popular neural network framework. This module identifies the object in a square region in the center of the camera field of view using a deep convolutional neural network.
The deep network analyzes the image by filtering it using many different filter kernels, and several stacked passes (network layers). This essentially amounts to detecting the presence of both simple and complex parts of known objects in the image (e.g., from detecting edges in lower layers of the network to detecting car wheels or even whole cars in higher layers). The last layer of the network is reduced to a vector with one entry per known kind of object (object class). This module returns the class names of the top scoring candidates in the output vector, if any have scored above a minimum confidence threshold. When nothing is recognized with sufficiently high confidence, there is no output.
This module runs a TensorFlow network and shows the top-scoring results. Larger deep networks can be a bit slow, hence the network prediction is only run once in a while. Point your camera towards some interesting object, make the object fit in the picture shown at right (which will be fed to the neural network), keep it stable, and wait for TensorFlow to tell you what it found. The framerate figures shown at the bottom left of the display reflect the speed at which each new video frame from the camera is processed, but in this module this just amounts to converting the image to RGB, sending it to the neural network for processing in a separate thread, and creating the demo display. Actual network inference speed (time taken to compute the predictions on one image) is shown at the bottom right. See below for how to trade-off speed and accuracy.
Note that by default this module runs different flavors of MobileNets trained on the ImageNet dataset. There are 1000 different kinds of objects (object classes) that these networks can recognize (too long to list here). The input layer of these networks is 299x299, 224x224, 192x192, 160x160, or 128x128 pixels by default, depending on the network used. This modules takes a crop at the center of the video image, with size determined by the USB video size: the crop size is USB output width - 2 - camera sensor image width. With the default network parameters, this module hence requires at least 320x240 camera sensor resolution. The networks provided on the JeVois microSD image have been trained on large clusters of GPUs, using 1.2 million training images from the ImageNet dataset.
For more information about MobileNets, see https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md
For more information about the ImageNet dataset used for training, see http://www.image-net.org/challenges/LSVRC/2012/
Sometimes this module will make mistakes! The performance of mobilenets is about 40% to 70% correct (mean average precision) on the test set, depending on network size (bigger networks are more accurate but slower).
Neural network size and speed
When using a video mapping with USB output, the cropped window sent to the network is automatically sized to a square size that is the difference between the USB output video width and the camera sensor input width minus 16 pixels (e.g., when USB video mode is 560x240 and camera sensor mode is 320x240, the network will be resized to 224x224 since 224=560-16-320).
The network actual input size varies depending on which network is used; for example, mobilenet_v1_0.25_128_quant expects 128x128 input images, while mobilenet_v1_1.0_224 expects 224x224. We automatically rescale the cropped window to the network's desired input size. Note that there is a cost to rescaling, so, for best performance, you should match the USB output width to be the camera sensor width + 2 + network input width.
For example:
- with USB output 464x240 (crop size 128x128), mobilenet_v1_0.25_128_quant (network size 128x128), runs at about 8ms/prediction (125 frames/s).
- with USB output 464x240 (crop size 128x128), mobilenet_v1_0.5_128_quant (network size 128x128), runs at about 18ms/prediction (55 frames/s).
- with USB output 560x240 (crop size 224x224), mobilenet_v1_0.25_224_quant (network size 224x224), runs at about 24ms/prediction (41 frames/s).
- with USB output 560x240 (crop size 224x224), mobilenet_v1_1.0_224_quant (network size 224x224), runs at about 139ms/prediction (7 frames/s).
When using a videomapping with no USB output, the image crop is directly taken to match the network input size, so that no resizing occurs.
Note that network dims must always be such that they fit inside the camera input image.
To easily select one of the available networks, see JEVOIS:/modules/JeVois/TensorFlowSingle/params.cfg on the microSD card of your JeVois camera.
Serial messages
When detections are found with confidence scores above thresh, a message containing up to top category:score pairs will be sent per video frame. Exact message format depends on the current serstyle setting and is described in Standardized serial messages formatting. For example, when serstyle is Detail, this module sends:
DO category:score category:score ... category:score
where category is a category name (from namefile) and score is the confidence score from 0.0 to 100.0 that this category was recognized. The pairs are in order of decreasing score.
See Standardized serial messages formatting for more on standardized serial messages, and Helper functions to convert coordinates from camera resolution to standardized for more info on standardized coordinates.
Using your own network
For a step-by-step tutorial, see Training custom TensorFlow networks for JeVois.
This module supports RGB or grayscale inputs, byte or float32. You should create and train your network using fast GPUs, and then follow the instruction here to convert your trained network to TFLite format:
https://www.tensorflow.org/lite/
Then you just need to create a directory under JEVOIS:/share/tensorflow/ with the name of your network, and, in there, two files, labels.txt with the category labels, and model.tflite with your model converted to TensorFlow Lite (flatbuffer format). Finally, edit JEVOIS:/modules/JeVois/TensorFlowEasy/params.cfg to select your new network when the module is launched.
| Parameter | Type | Description | Default | Valid Values |
|---|---|---|---|---|
| (TensorFlow) netdir | std::string | Network to load. This should be the name of a directory within JEVOIS:/share/tensorflow/ which should contain two files: model.tflite and labels.txt | mobilenet_v1_224_android_quant_2017_11_08 | - |
| (TensorFlow) dataroot | std::string | Root path for data, config, and weight files. If empty, use the module's path. | JEVOIS_SHARE_PATH /tensorflow | - |
| (TensorFlow) top | unsigned int | Max number of top-scoring predictions that score above thresh to return | 5 | - |
| (TensorFlow) thresh | float | Threshold (in percent confidence) above which predictions will be reported | 20.0F | jevois::Range<float>(0.0F, 100.0F) |
| (TensorFlow) threads | int | Number of parallel computation threads, or 0 for auto | 4 | jevois::Range<int>(0, 1024) |
| (TensorFlow) scorescale | float | Scaling factors applied to recognition scores, useful for InceptionV3 | 1.0F | - |
params.cfg file# Config for TensorFlowSingle. Just uncomment the network you want to use: # The default network provided with TensorFlow Lite: #netdir=mobilenet_v1_224_android_quant_2017_11_08 # All mobilenets with different input sizes, compression levels, and quantization. See # https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md # for some info on how to pick one. #netdir=mobilenet_v1_0.25_128 #netdir=mobilenet_v1_0.25_128_quant #netdir=mobilenet_v1_0.25_160 #netdir=mobilenet_v1_0.25_160_quant #netdir=mobilenet_v1_0.25_192 #netdir=mobilenet_v1_0.25_192_quant #netdir=mobilenet_v1_0.25_224 #netdir=mobilenet_v1_0.25_224_quant #netdir=mobilenet_v1_0.5_128 netdir=mobilenet_v1_0.5_128_quant #netdir=mobilenet_v1_0.5_160 #netdir=mobilenet_v1_0.5_160_quant #netdir=mobilenet_v1_0.5_192 #netdir=mobilenet_v1_0.5_192_quant #netdir=mobilenet_v1_0.5_224 #netdir=mobilenet_v1_0.5_224_quant #netdir=mobilenet_v1_0.75_128 #netdir=mobilenet_v1_0.75_128_quant #netdir=mobilenet_v1_0.75_160 #netdir=mobilenet_v1_0.75_160_quant #netdir=mobilenet_v1_0.75_192 #netdir=mobilenet_v1_0.75_192_quant #netdir=mobilenet_v1_0.75_224 #netdir=mobilenet_v1_0.75_224_quant #netdir=mobilenet_v1_1.0_128 #netdir=mobilenet_v1_1.0_128_quant #netdir=mobilenet_v1_1.0_160 #netdir=mobilenet_v1_1.0_160_quant #netdir=mobilenet_v1_1.0_192 #netdir=mobilenet_v1_1.0_192_quant #netdir=mobilenet_v1_1.0_224 #netdir=mobilenet_v1_1.0_224_quant # Quite slow but accurate, about 4s/prediction, and scores seem out of scale somehow: #netdir=inception_v3_slim_2016_android_2017_11_10 #scorescale=0.07843 |
| Detailed docs: | TensorFlowSingle |
|---|---|
| Copyright: | Copyright (C) 2017 by Laurent Itti, iLab and the University of Southern California |
| License: | GPL v3 |
| Distribution: | Unrestricted |
| Restrictions: | None |
| Support URL: | http://jevois.org/doc |
| Other URL: | http://iLab.usc.edu |
| Address: | University of Southern California, HNB-07A, 3641 Watt Way, Los Angeles, CA 90089-2520, USA |