|
| By Laurent Itti | itti@usc.edu | http://jevois.org | GPL v3 |
| |||
| Video Mapping: YUYV 320 262 15.0 YUYV 320 240 15.0 JeVois PythonObject6D |
Module Documentation
This module implements an object detector using ORB keypoints using OpenCV in Python. Its main goal is to also demonstrate full 6D pose recovery of the detected object, in Python, as well as locating in 3D a sub-element of the detected object (here, a window within a larger textured wall). See ObjectDetect for more info about object detection using keypoints. This module is available with JeVois v1.6.3 and later.
The algorithm consists of 5 phases:
- detect keypoint locations, typically corners or other distinctive texture elements or markings;
- compute keypoint descriptors, which are summary representations of the image neighborhood around each keypoint;
- match descriptors from current image to descriptors previously extracted from training images;
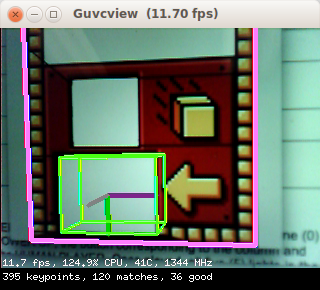
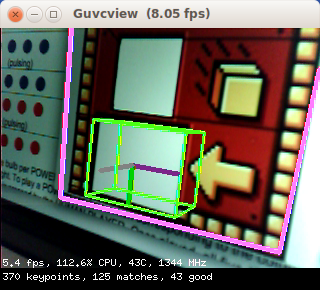
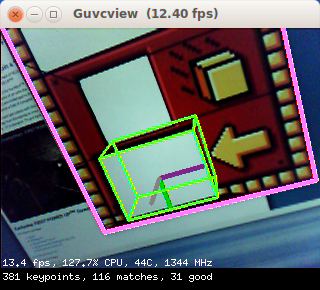
- if enough matches are found between the current image and a given training image, and they are of good enough quality, compute the homography (geometric transformation) between keypoint locations in that training image and locations of the matching keypoints in the current image. If it is well conditioned (i.e., a 3D viewpoint change could well explain how the keypoints moved between the training and current images), declare that a match was found, and draw a pink rectangle around the detected whole object.
- finally perform 6D pose estimation (3D translation + 3D rotation), here for a window located at a specific position within the whole object, given the known physical sizes of both the whole object and the window within. A green parallelepiped is drawn at that window's location, sinking into the whole object (as it is representing a tunnel or port into the object).
For more information about ORB keypoint detection and matching in OpenCV, see, e.g., https://docs.opencv.org/3.4.0/d1/d89/tutorial_py_orb.html
This module is provided for inspiration. It has no pretension of actually solving the FIRST Robotics Power Up (sm) vision problem in a complete and reliable way. It is released in the hope that FRC teams will try it out and get inspired to develop something much better for their own robot.
Note how, contrary to FirstVision, DemoArUco, etc, the green parallelepiped is drawn going into the object instead of sticking out of it, as it is depicting a tunnel at the window location.
Using this module
This module is for now specific to the "exchange" of the FIRST Robotics 2018 Power Up (sm) challenge. See https://www.firstinspires.org/resource-library/frc/competition-manual-qa-system
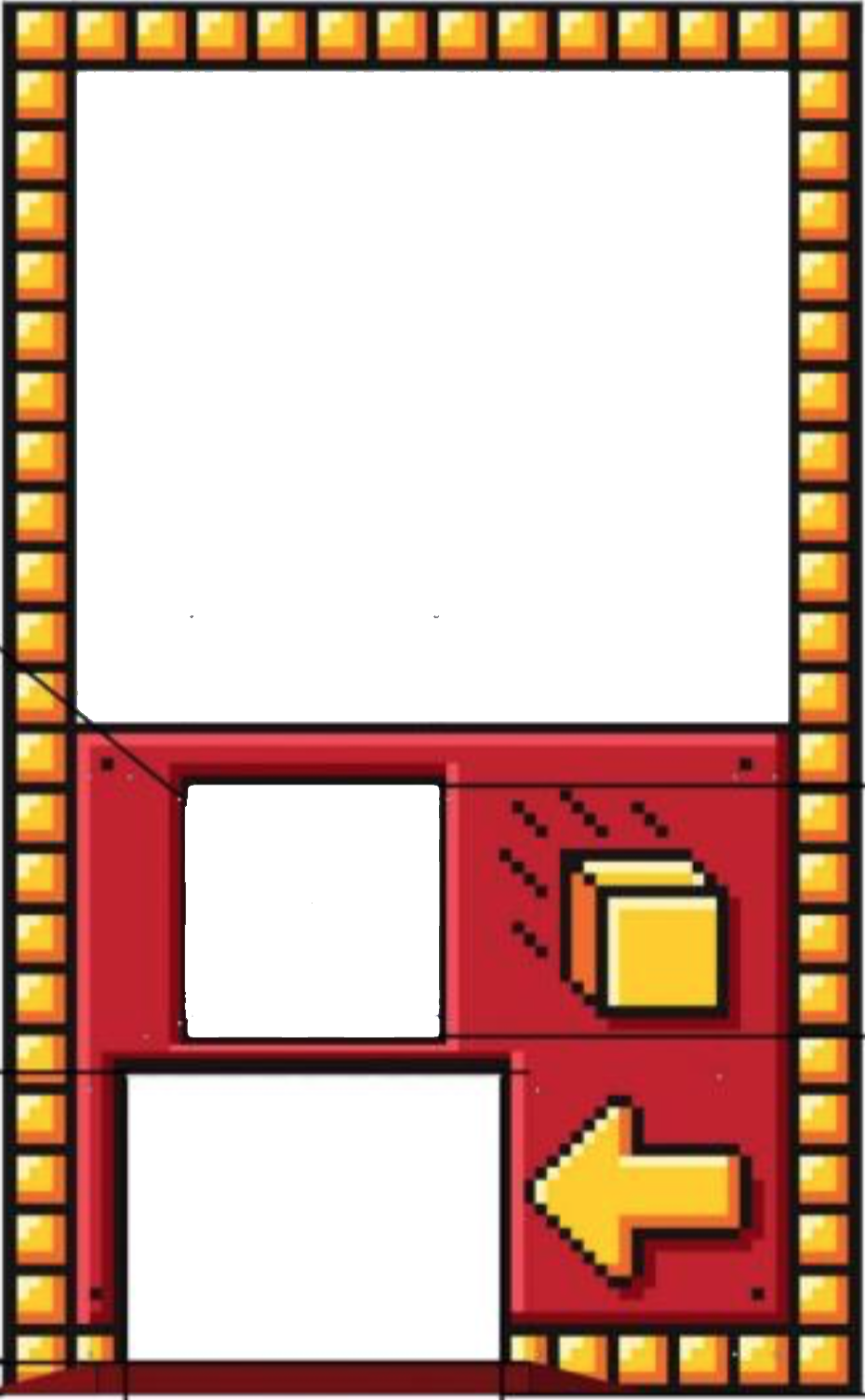
The exchange is a large textured structure with a window at the bottom into which robots should deliver foam cubes.
A reference picture of the whole exchange (taken from the official rules) is in JEVOIS:/modules/JeVois/PythonObject6D/images/reference.png on your JeVois microSD card. It will be processed when the module starts. No additional training procedure is needed.
If you change the reference image, you should also edit:
- values of
self.owmandself.ohmto the width ahd height, in meters, of the actual physical object in your picture. Square pixels are assumed, so make sure the aspect ratio of your PNG image matches the aspect ratio in meters given by variablesself.owmandself.ohmin the code. - values of
self.wintop,self.winleft,self.winw,self.winhto the location of the top-left corner, in meters and relative to the top-left corner of the whole reference object, of a window of interest (the tunnel into which the cubes should be delivered), and width and height, in meters, of the window.
TODO: Add support for multiple images and online training as in ObjectDetect
Things to tinker with
There are a number of limitations and caveats to this module:
- It does not use color, the input image is converted to grayscale before processing. One could use a different approach to object detection that would make use of color.
- Results are often quite noisy. Maybe using another detector, like SIFT which provides subpixel accuracy, and better pruning of false matches (e.g., David Lowe's ratio of the best to second-best match scores) would help.
- This algorithm is slow in this single-threaded Python example, and frame rate depends on image complexity (it gets slower when more keypoints are detected). One should explore parallelization, as was done in C++ for the ObjectDetect module. One could also alternate between full detection using this algorithm once in a while, and much faster tracking of previous detections at a higher framerate (e.g., using the very robust TLD tracker (track-learn-detect), also supported in OpenCV).
- If you want to detect smaller objects or pieces of objects, and you do not need 6D pose, you may want to use modules ObjectDetect or SaliencySURF as done, for example, by JeVois user Bill Kendall at https://www.youtube.com/watch?v=8wYhOnsNZcc
| Parameter | Type | Description | Default | Valid Values |
|---|---|---|---|---|
| This module exposes no parameter | ||||
| Detailed docs: | PythonObject6D |
|---|---|
| Copyright: | Copyright (C) 2018 by Laurent Itti, iLab and the University of Southern California |
| License: | GPL v3 |
| Distribution: | Unrestricted |
| Restrictions: | None |
| Support URL: | http://jevois.org/doc |
| Other URL: | http://iLab.usc.edu |
| Address: | University of Southern California, HNB-07A, 3641 Watt Way, Los Angeles, CA 90089-2520, USA |