|
JeVois
1.23
JeVois Smart Embedded Machine Vision Toolkit
|
|
|
JeVois
1.23
JeVois Smart Embedded Machine Vision Toolkit
|
|
Some hardware accelerators running JeVois-Pro require that the DNN models be optimized, quantized, and converted to the operation set supported by the hardware, before they can run in the camera. In this tutorial, we explore conversion for the following runtime frameworks:
OpenCV: Accepts many models as-is, and is quite fast at runtime compared to native frameworks (e.g., Caffe). However, mainly runs on CPU, which is slow compared to dedicated neural accelerators. Exceptions include:
The JeVois DNN framework supports OpenCV with CPU, Myriad-X, and TIM-VX, through the NetworkOpenCV class.
Network quantization is the process of converting network weights from 32-bit float values that are usually used on server-grade GPUs to smaller representations, e.g., 8-bit wide. This makes the model smaller, faster to load, and faster to execute using dedicated embedded hardware processors that are designed to operate using 8-bit weights.
When quantizing, the goal is to use as much of the reduced available bits to represent the original float values. For example, if float values are known to always be, during training, in some range, say, [-12.4 .. 24.7], then one would want to quantize such that -12.4 would become quantized 0, and 24.7 would become quantized 255. In that way, the whole 8-bit range [0..255] will be used to represent the original float numbers with maximal accuracy given the reduction to 8 bits.
Thus, successful quantization requires that one has a good idea of the range of values that every layer in a network will be processing. This is achieved either during training (by using so-called quantization-aware training that will keep track of the range of values for every layer during training), or afterwards using a representative sample dataset (post-training quantization where the sample dataset will be passed through the already trained network and the range of values processed at every layer will be recorded).
JeVois supports the following quantization methods:
Weights are represented as an unsigned 8-bit value [0..255], plus scale and zero-point attributes that describe how that 8-bit value is to be interpreted as a floating point number:
Usually, only one scale and zero-point are used for a whole network layer, so that we do not have to carry these extra parameters for every weight in the network.
For example, say a network originally expected float input values in [0.0 .. 1.0]. We can quantize that using scale = 1/255 and zero_point = 0. Now 0.0 maps to 0 and 1.0 maps to 255.
If the network used inputs in [-1.0 .. 1.0], we can quantize using scale = 1/127.5 and zero-point = 127.5.
Weights are represented as integer values (typically signed int8 or signed int16) that have a special bitwise interpretation:
Typically, dynamic fixed point specs only specify the fl value, with the understanding that m is just the number of bits in the chosen type (e.g., 8 for 8-bit) minus 1 bit reserved for sign and minus fl bits for the decimal part.
DFP is also specified for a whole layer, so that we do not have to carry a different fl value for every weight in the network.
JeVois uses the following specification to describe input and output tensors of neural networks:
[NCHW:|NHWC:|NA:|AUTO:]Type:[NxCxHxW|NxHxWxC|...][:QNT[:fl|:scale:zero]]
First field (optional): A hint on how channels (typically, red, green, and blue for color input tensors) are organized; either:
Mainly this is used as some networks do expect planar ordering (which is somewhat easier to use from the standpoint of a network designer, since one can just process the various color planes independently; but it is not what most image formats like JPEG, PNG, etc or camera sensors provide), while others expect packed pixels (which may make a network design more complex, but has the advantage that now images in native packed format can directly be fed to the network).
NONE (no quantization, assumed if no quantization spec is given), DFP:fl (dynamic fixed point, with fl bits for the decimal part; e.g., int8 with DFP:7 can represent numbers in [-0.99 .. 0.99] since the most significant bit is used for sign, 0 bits are used for the integer part, and 7 bits are used for the decimal part), or AA:scale:zero_point (affine asymmetric). In principle, APS (affine per-channel asymmetric) is also possible, but we have not yet encountered it and thus it is currently not supported (let us know if you need it).Internally, JeVois uses the vsi_nn_tensor_attr_t struct from the NPU SDK to represent these specifications, as this is the most general one compared to their equivalent structures provided by TensorFlow, OpenCV, etc. This struct and the related specifications for quantization type, etc are defined in https://github.com/jevois/jevois/blob/master/Contrib/npu/include/ovxlib/vsi_nn_tensor.h
Most DNN use some form of pre-processing, which is to prepare input pixel values into a range that the network is expecting. This is separate from quantization but we will see below that the two can interact.
For example, a DNN designer may decide that float input pixel values in the range [-1.0 .. 1.0] give rise to the easiest to train, best converging, and best performing network. Thus, when images are presented to the original network that uses floats, pre-processing consists of first converting pixel values from [0 .. 255], as usually used in most image formats like PNG, JPEG, etc, into that [-1.0 .. 1.0] range.
Most pre-trained networks should provide the following pre-processing information along with the pre-trained weights:
Usually either one of scale or stdev is specified, but in rare occasions both may be used. The mean and stdev values are triplets for red, green, and blue, while the scale value is a single scalar number.
Pre-processing then computes the float pixel values to be fed into the network from the original uint8 ones from an image or camera frame as follows:
Pre-processing is specified by a network designer that designed a network to operate on float values. It is originally unrelated to quantization, which is desired by people who want to run networks efficiently on hardware accelerators. Yet, as mentioned above, the two may interact, and sometimes actually cancel each other. For example:
In the end, first pre-processing and then quantizing would result in a no-op:
The JeVois PreProcessorBlob detects special cases such as this one, and provides no-op or optimized implementations.
Full pre-processing involves some additional steps, such as resizing the input image, possibly swapping RGB to BGR, and possibly unpacking from packed RGB to planar RGB, as detailed in the docs for PreProcessorBlob
When a quantized network is run, it typically outputs quantized representations.
Post-processing hence will do two things:
Sometimes, dequantization is not necessary; for example, semantic segmentation networks often just output a single array of uint8 values, where the values are directly the assigned object class number for every pixel in the input image.
When using quantized networks, one may face two problems:
Quantization issues when several disparate tensors are merged in a network. Recent YOLO architectures detect bounding boxes and class probabilities in different branches of the network. They then concatenate both into just one big tensor. When using quantized networks, this is a problem:
If we concatenate both, the final dynamic range is [0 .. 1024[. Representing that in a quantized network with 8-bit precision would call for a quantization zero point of 0 and scale of 4, such that [0 .. 1024[ is represented by quantized values [0 .. 256[. With a scale of 4, however, we cannot distinguish numbers in [0.0 .. 1.0] for class probabilities:
In particular, all original float values in [0.0 .. 1.0[ map to quantized 0, so we cannot recover class probabilities form the quantized tensor, they will all always be 0.
Let's have a look at the bottom of YOLOv8n-512x288 in Netron (input size is 1x3x288x512):
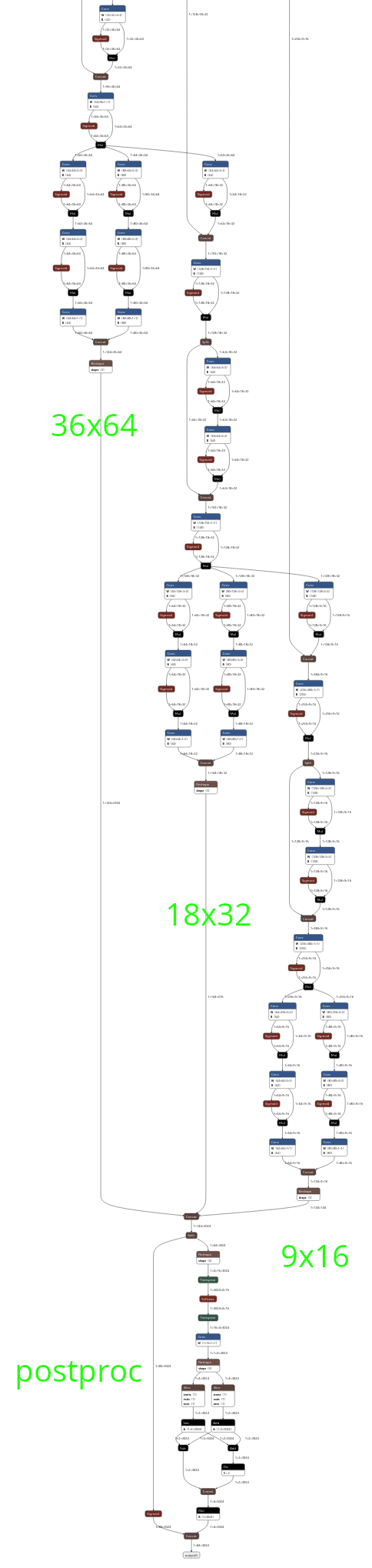
(click on image to enlarge)
We have 3 detection branches for 3 different scales or 'strides', with resolutions 36x64, 18x32, and 9x16. Then they all get concatenated and some post-processing is applied.
Zooming in on the 36x64 branch:
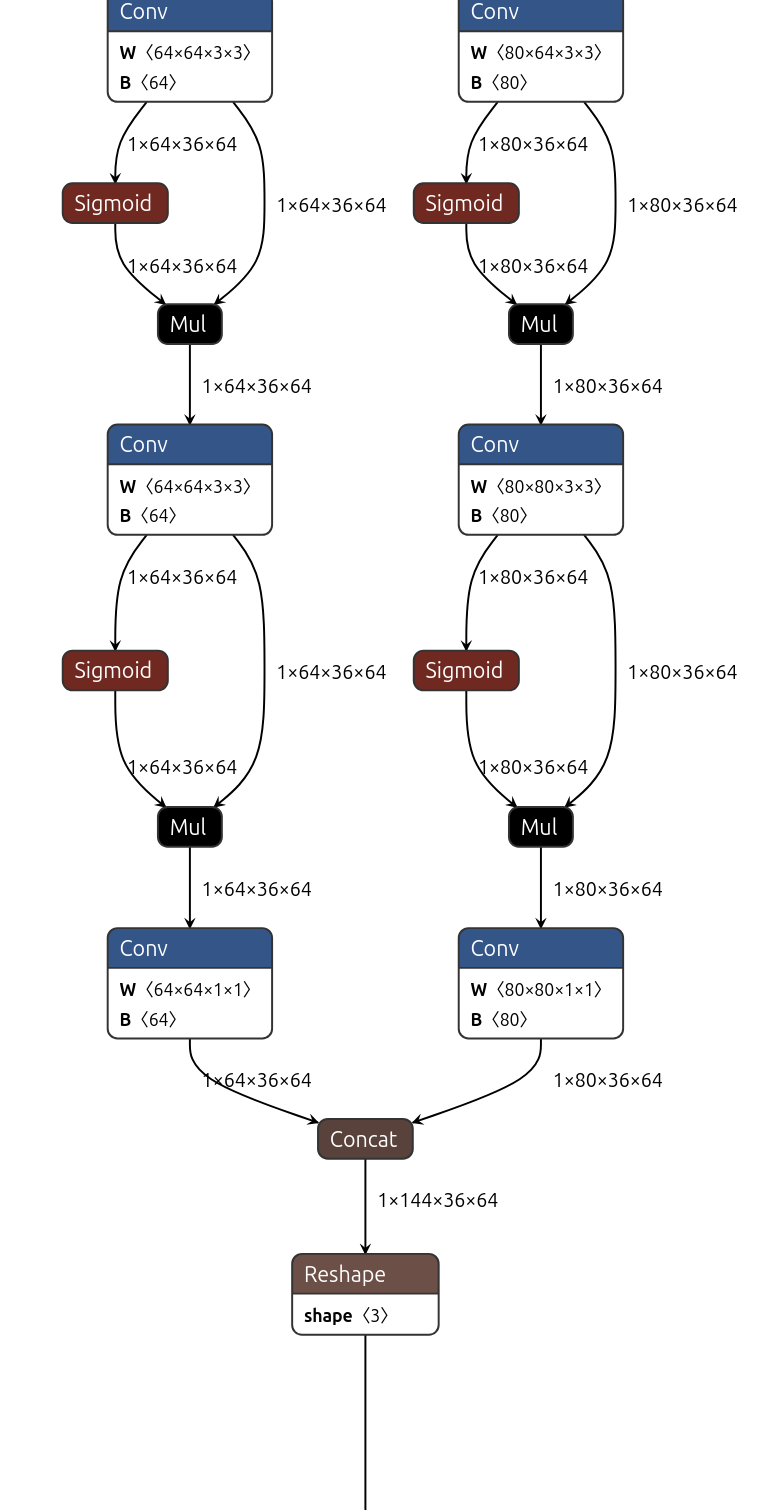
(click on image to enlarge)
We see that two Conv outputs are concatenated: 1x64x36x64 (these are the raw boxes, before decoding of the Distributed Focal Loss representation), and 1x80x36x64 (these are the class probabilities for 80 classes on the COCO dataset).
For quantized operation, we want to get these two Conv outputs before the concatenation as two separate output tensors, and likewise for the 2 other strides. Total 6 outputs. We bypass the post-processing entirely and will run it on CPU. Have a look at the models in JeVois-Pro Deep Neural Network Benchmarks for many examples of the kinds of outputs we extract from various models to work with our C++ or Python post-processors.
The general procedure and details for each available framework are described in the following pages:
 1.9.8
1.9.8

{kind=link}
{kind=link}